作者:原创

UALink联盟成立于去年,它的一个关键目标是为AI加速器打造一个具有竞争力的连接生态系统,以挑战英伟达已有的NVLink技术。英伟达凭借NVLink技术构建了诸如Blackwell NVL72这样的机架级AI优化解决方案,从而在AI加速器市场占据主导地位。这个联盟由九大巨头牵头,包括AMD、亚马逊网络服务 (AWS)、Astera Labs、思科、谷歌、惠普企业 (HPE)、英特尔、Meta和微软。

如今,Ualink联盟正式发布UALink 1.0。这意味着该小组的成员现在可以继续对支持新技术的实际芯片进行流片。这种新的互连技术针对AI和高性能计算(HPC)加速器,得到了包括AMD、苹果、博通和英特尔在内的广泛行业参与者的支持。它有望成为连接此类硬件的行业标准。
UALink 1.0定义了一种高速、低延迟的加速器互连,支持每通道最大双向数据速率200 GT/s,信号速率为212.5 GT/s,以适应前向纠错和编码开销。UALink可以配置为x1、x2或x4,四通道链路在发送和接收方向上均可达到800 GT/s。
一个UALink系统支持多达1024个加速器(GPU或其他)通过UALink交换机连接,每个加速器分配一个端口和一个10位唯一标识符,用于精确路由。UALink电缆长度针对小于4米进行了优化,能够实现小于1微秒的往返延迟,支持64B/640B负载。这些链路支持跨1到4个机架的确定性性能。
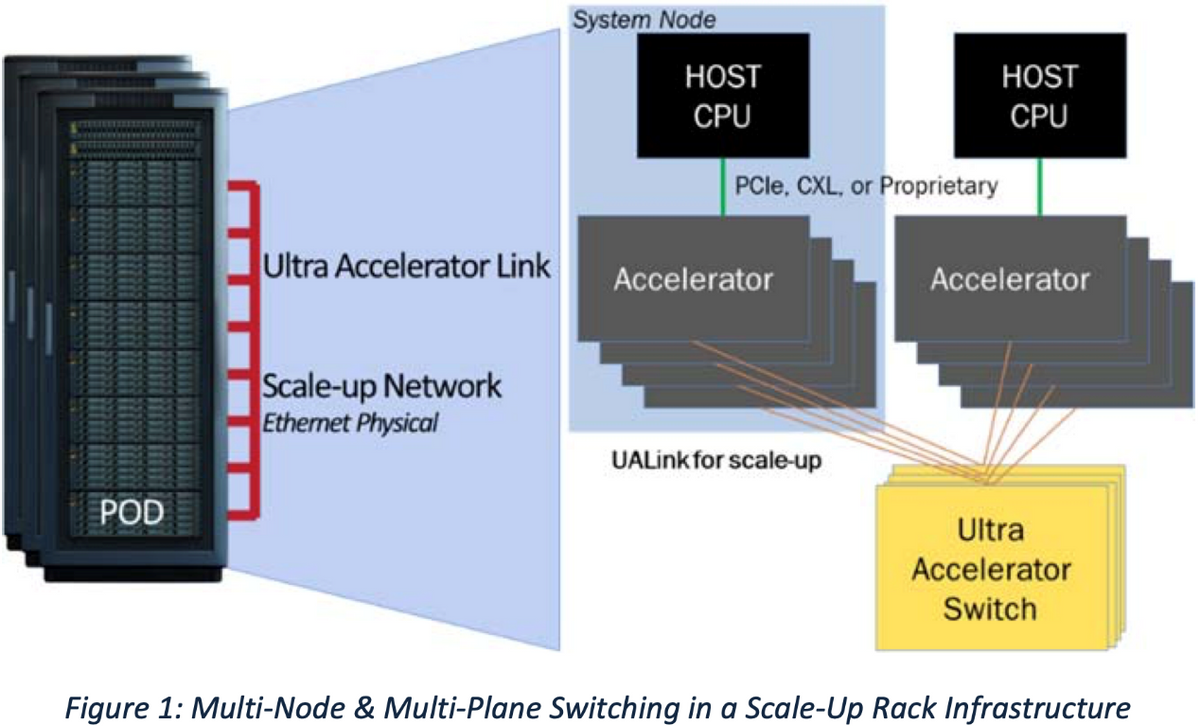
UALink协议栈包括四个硬件优化层:物理层、数据链路层、事务层和协议层。物理层使用标准以太网组件(例如200GBASE-KR1/CR1),并进行了减少延迟的前向纠错(FEC)修改。数据链路层将事务层的64字节数据块封装成640字节单元,应用CRC和可选的重试逻辑。该层还处理设备间消息传递,并支持类似UART的固件通信。
事务层实现了压缩寻址,通过在真实工作负载下实现高达95%的协议效率来优化数据传输。它还支持加速器之间的直接内存操作,如读取、写入和原子事务,同时保持本地和远程内存空间中的顺序。
由于针对现代数据中心,UALink协议支持集成的安全和管理功能。例如,UALinkSec在硬件级别对所有流量进行加密和身份验证,防止物理篡改,并通过租户控制的信任执行环境(如AMD SEV、Arm CCA和英特尔TDX)支持机密计算。该规范允许通过交换机级配置在单个Pod内隔离加速器组,从而在共享基础设施上实现多租户工作负载的并发运行。
UALink Pod将通过专用的控制软件和固件代理进行管理,这些代理使用PCIe和以太网等标准接口。通过REST API、遥测、工作负载控制和故障隔离,支持完整的可管理性。
UALink联盟主席彼得·奥努夫里克(Peter Onufryk)表示:“随着UALink 200G 1.0规范的发布,UALink联盟的成员公司正在积极构建一个开放的扩展加速器连接生态系统。我们期待看到即将进入市场的各种解决方案,并期待它们为未来的AI应用提供支持。”
英伟达目前在AI加速器市场占据主导地位,这得益于其强大的生态系统和扩展解决方案。它目前正出货使用NVLink连接单个机架中多达72个GPU的Blackwell NVL72机架,跨机架Pod允许单个Pod中多达576个Blackwell B200 GPU。凭借其将于明年推出的Vera Rubin平台,英伟达计划将单个机架中的GPU扩展到144个,而2027年的Rubin Ultra将把单个机架中的GPU扩展到576个。
