作者:原创

在2025年AI发展大会(AMD Advancing AI)上,AMD董事会主席及首席执行官苏姿丰发布了新的MI350X和MI355X AI GPU,并剧透了预计明年推出的MI400,以及构建开放AI 生态系统的进展。此外,她强调了全新的、开放的机架级设计及路线图。AMD展示了其史上最强的旗舰数据中心AI芯片、AI软件栈、AI机架级基础设施、AI网卡与DPU,全面宣战英伟达。

MI350系列GPU算力提升4倍
AMD履行Instinct GPU路线图承诺,继2023年发布MI300A/X、2024年推出MI325后,MI350系列今年第三季度上市,下一代MI400系列将在明年推出。

MI350系列GPU是AMD当前最先进的生成式AI平台。MI350X和MI355X采用相同的计算机体系结构和内存,均支持高达288GB的HBM3E内存和高达8TB/s的内存带宽,并新增了对FP4和FP6数据类型的支援。MI350X更适用于典型板卡功耗(TBP)较低的风冷,MI355X的训练吞吐量、效率、功耗更高,更适用于液冷。

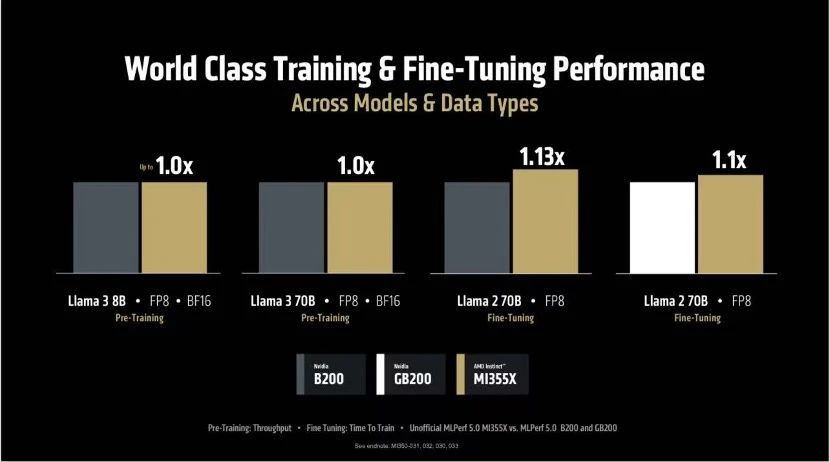
AMD声称这些新的加速器相比上一代的MI300X性能提升了3倍,这使得AMD在与市场领先的竞争对手英伟达的竞争中更具竞争力。AMD声称其在同类推理基准测试中比英伟达的产品快1.3倍,在某些训练工作负载中领先1.13倍。
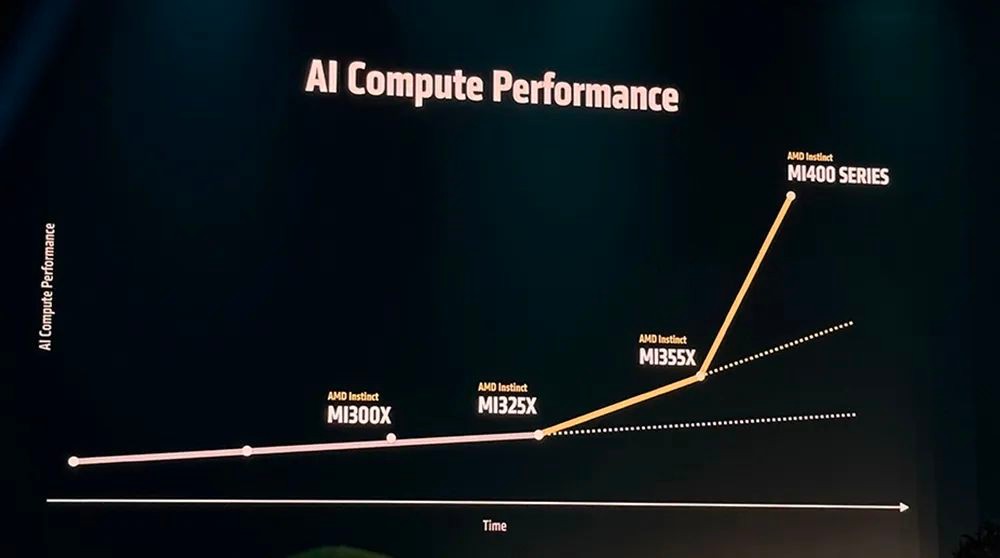
据介绍,与上一代的AMD MI300X型号相比,新GPU的“AI计算性能”提高了4倍,推理性能提高了35倍,这主要得益于向CDNA 4架构的转变以及使用更小、更先进的工艺节点来制造计算芯片。AMD的MI350平台已于上个月开始出货。

AMD的MI355X配备了比Nvidia竞争的GB200和B200 GPU多1.6倍的HBM3E内存容量,但提供了相同的8TB/s内存带宽。AMD声称其在峰值FP64/FP32性能上比Nvidia的芯片有2倍的优势。值得注意的是,与MI300X相比,MI350的FP64矩阵性能减半,而向量性能则大约下降了4%。
该芯片共有8个XCD芯片,每个芯片启用32个计算单元(CU),总共256个CU(AMD每个XCD保留4个CU以提高产量,根据需要禁用这些单元)。XCD从上一代的5纳米工艺转变为采用台积电N3P工艺节点制造的MI350系列。整个芯片拥有1850亿个晶体管,比上一代的1530亿个晶体管增加了21%。
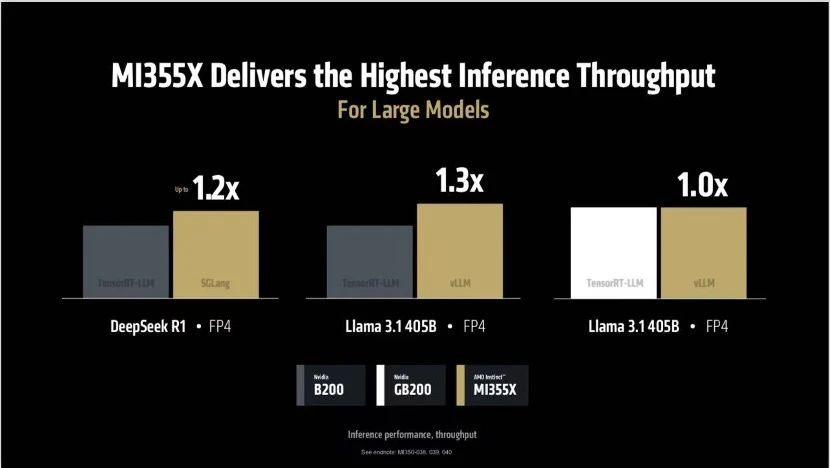
AMD声称,一个8GPU的MI355X设置在Llama 3.1 405B中,与4个MI355X相比,比4个DGX GB200快1.3倍;在DeepSeek R1的推理中,与8个GPU的B200 HGX配置相比,8个MI355X快1.2倍,而在Llama 3.1 405B中表现相当(所有测试均在FP4下进行)。
AMD表示,与MI300X相比,MI355X在AI代理和聊天机器人工作负载中提供了高达4.2倍的性能提升,同时在内容生成、总结和对话式AI工作中实现了2.6倍到3.8倍的强劲增长。其他代际亮点包括在DeepSeek R1中实现了3倍的代际改进,在Llama 4 Maverick中实现了3.3倍的提升。

ROCm 7推理性能提升超过3.5倍
相较于硬件的升级,AMD在与英伟达的竞争中,真正的挑战还在于ROCm软件生态系统的建设。ROCm 7将于2025年第三季度普遍可用,AMD发布一个公开预览版,官方版本将于8月发布,支持MI350系列GPU。
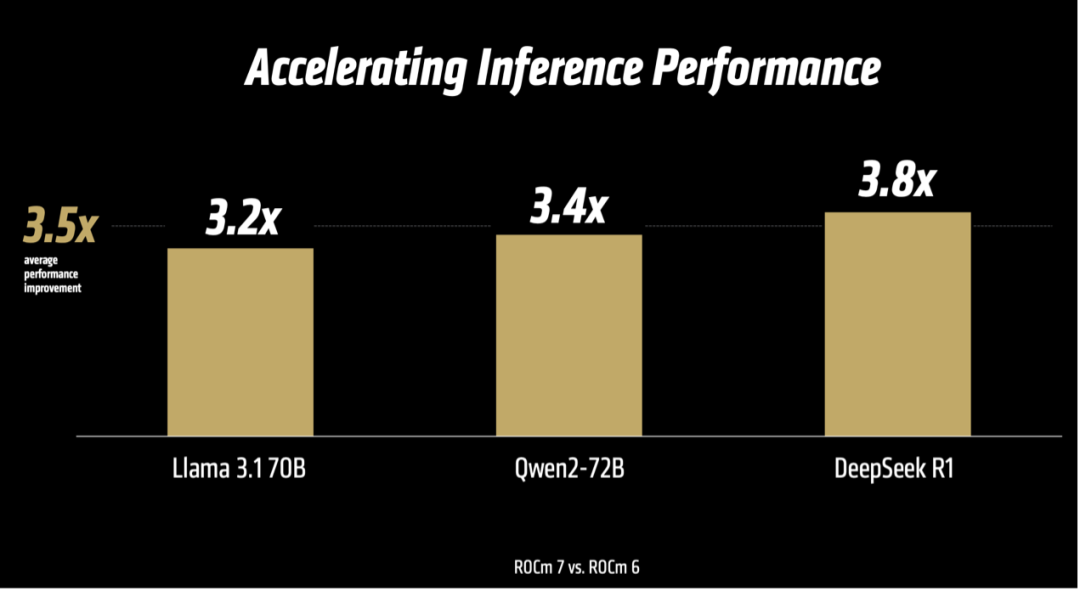
与上一代ROCm 6版本相比,ROCm 7拥有超过3.5倍的推理能力和3倍的训练能力。这源于可用性、性能和对低精度数据类型(如FP4和FP6)支持等方面的进步,通信栈的进一步增强优化了GPU利用率和数据移动。
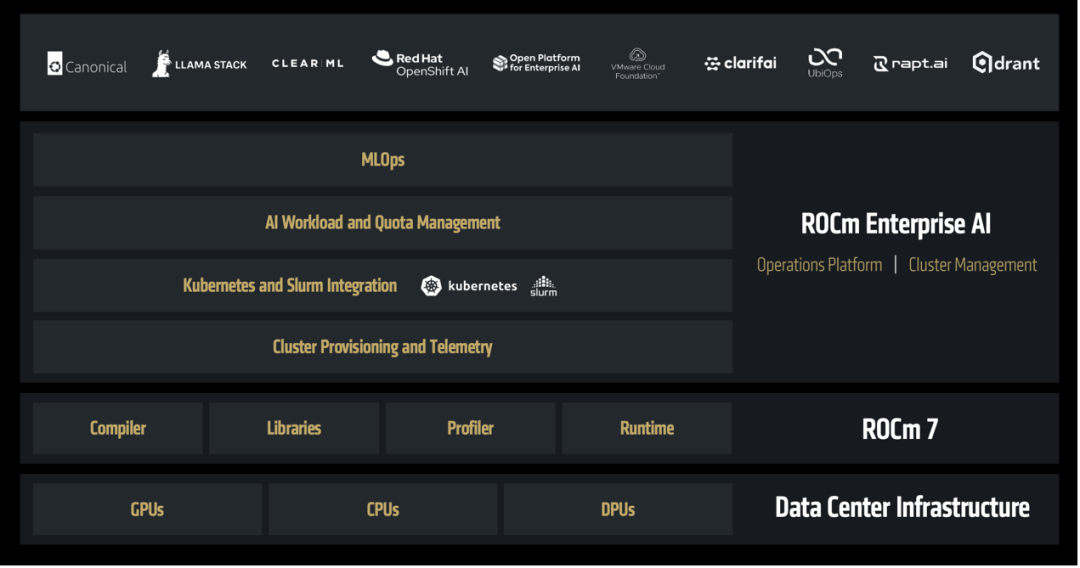
苏姿丰强调,随着AI应用从研究转向真实世界的企业部署,ROCm 也在同步演进。ROCm企业级AI将一套全栈式MLOps 平台推向台前,凭借支持超过180万个Hugging Face 模型的开箱即用体验,以及行业基准测试的引入,ROCm提供用于微调、合规、部署和集成的开箱即用工具,以实现安全、可扩展的AI。
ROCm将支持In-Box Linux,并首度支持Windows操作系统。预计从2025年下半年开始,ROCm将出现在主要的发行版中,将Windows定位为一流的、得到全面支持的操作系统,确保家庭和企业设置的可移植性和效率。AMD还首次推出开发者云。

MI400系列与 “Helios” AI机架明年见
据介绍,AMD Instinct MI400系列将实现巨大的跨代性能飞跃,为大规模训练和分布式推理提供完整的机柜级解决方案。其关键性能创新包括:432GB的HBM4内存;19.6TB/s的内存带宽;40 PFLOPS的FP4性能和20 PFLOPS的FP8性能;300GB/s 的横向扩展带宽。

相比MI355X,MI400系列的性能提升高达10倍,可实现跨机架和集群的高带宽互连,旨在训练和运行拥有数千亿和万亿级参数的大模型。
下一代“Helios”AI机架是AMD首个AI机架级解决方案,支持多达72块MI400系列GPU紧密耦合,支持260TB/s的扩展带宽,支持UALink,FP4峰值算力达2.9EFLOPS。
与采用英伟达下一代Vera Rubin芯片的Oberon机架相比,Helios AI机架拥有同等的GPU域、纵向扩展带宽,FP4和FP8精度下的性能也大致相同,HBM4内存容量、内存带宽、横向扩展带宽分别提升50%。

Helios集成了AMD EPYC “Venice” CPU、MI400系列GPU和Pensando “Vulcano” NIC网卡。其中AMD EPYC “Venice”服务器CPU将采用2nm制程,基于Zen 6架构,最多256核,CPU-to-GPU带宽翻倍,代际性能提升70%,内存带宽达到1.6TB/s。

苏姿丰还剧透了将于2027年推出的AMD下一代机架级解决方案。该方案将集成EPYC “Verano” CPU、MI500系列GPU、Pensando “Vulcano” NIC。
AMD是唯一具备全面覆盖数据中心、边缘及终端设备端到端AI能力的供应商,拥有支撑全栈AI所需的广度产品阵容与深厚软件实力。作为全球数据中心AI芯片市场的第二名,AMD对竞争对手英伟达虎视眈眈。
