作者:原创

AI的宏大叙事,已经贯穿从云端到边端的各个计算细分市场,特别是2024年以来,客户端产品中的PC和智能手机无一不打出AI化概念,加速AI相关应用和设备的推进普及。

数据显示,全球约有58%的企业都会运用到生成式AI;预计到2026年,生成式AI市场规模有望增长至3000亿美元,这其中包括硬件、软件、解决方案等;到2028年,大约80%以上的PC产品将会转换成AI PC;届时,人们将通过AI PC提高工作效率,释放更多的生产力和创造力。
在另一端的云上,更恰当的说,在高算力节点上,AI增强及转向后的CPU,正成为GPU外的另一极。英特尔第五代至强可扩展处理器在这样的大背景下诞生,也因此针对AI应用相关需求,提供了增强型的支持。
英特尔第五代至强可扩展处理器大幅提升了硬件规格、改进了芯片架构。这款代号为Emerald Rapids处理器,内置了英特尔AMX、英特尔SGX/TDX等多种专用加速器。但是,开发人员无需在代码编写时过多考虑运行硬件问题,仅需利用OpenVINO,就可实现应用的“一次编写,任何硬件、任何模型、任何地方部署”,英特尔开发的基础软件和数据库通过Pytorch和ONNX Runtime等流行框架支持自身的 CPU、GPU、IPU和AI加速器。
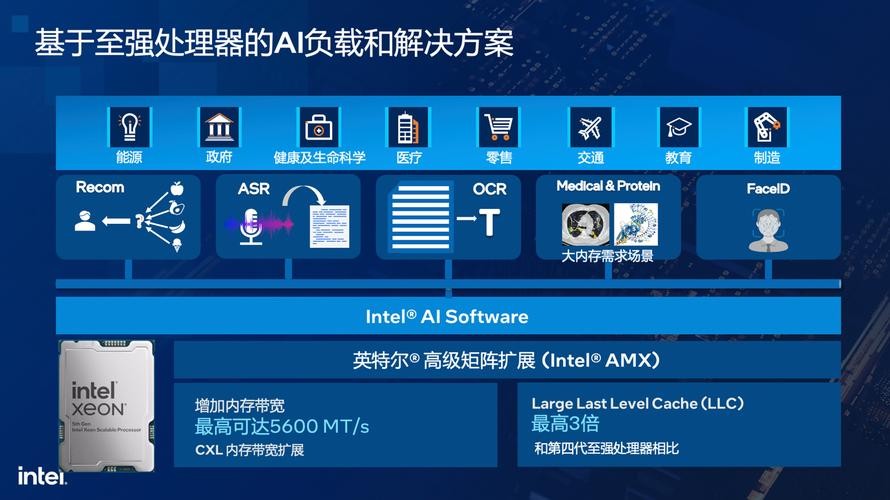
硬件方面,第五代至强可扩展处理器在支持英特尔AVX-512及英特尔AMX相关加速指令得到进一步增强,其中AMX支持新的FP16指令,同时混合AI工作负载性能提高2~3倍。
面向包括AI应用在内的企业级需求,这一代产品的CPU核心数量增加到64个,单核性能更高,每个内核都具备AI加速功能;同时核心封装从4代产品的4个tile缩减到2个几乎对称架构的更大的tile,核心间延迟更低、功耗更低,而制造良率更高;采用全新I/O技术(CXL、PCI-E 5.0),UPI 2.0速度提升至高达20 GT/s;在推理大模型方面,内存带宽是系统的重要瓶颈,第五代至强可扩展处理器支持的内存带宽从4800 MT/s提高至5600 MT/s,三级缓存容量更是提升近3倍,最大达到320MB;该平台最多支持4个CXL Type 3内存扩展设备,最高组成12通道DDR5内存。

与4代产品相比,第五代至强可扩展处理器在相同TDP下平均性能提升21%,AI推理性能提升42%。
在京东云上的测试表明,与上一代京东云自研服务器相比,基于第五代至强可扩展处理器的新服务器整机性能提升123%;AI计算机视觉推理性能提升至138%;Llama 2推理性能提升至151%。幅度相当可观。

也许你会有疑问,与动辄数千个“核心”的GPU相比,CPU核心不过数十个,为何后者仍是AI计算时代不可或缺的主角。这就如同大侠与军队的差异,前者个人能力强,体现在高人一头的单项任务能力与十八般兵器样样精通方面,可以百万军中取上将首级。但是在攻城略地方面,个人的能力就显得非常有限了,而功能整齐划一、号令而动的军队,则拥有强大的整体战力,除了人数多,后勤准备(内存装载)、命令发布(延迟)对战斗胜负的影响同样重要。
选择何种计算及加速平台完成AI计算,与用户的应用需求有关。在传统计算应用领域,更大容量的缓存,对数据库型应用的加速更显著。通过算法优化后,高频度访问数据,甚至无需经过计算核心或外存操作,就能在缓存中直接获取,极大地降低了数据访问延迟。类似的情况也出现在推理型AI加速应用上,其数据规模庞大,使用靠近内存的缓存加速效果更好,可大幅减少从内存通过PCI-E通道装载至GPU内存(显存)的时间。
作为更为通用化的计算与AI加速平台,第五代至强可扩展处理器,可大大降低用户部署包括AI在内的应用实例的成本,无论是选择CPU内置、平台内置还是第三方加速器,其更强的CPU每核性能、更多核心、更低延迟、更强扩展能力,都在不断地增加“大侠”的“战力”。
